In my previous Tensorflow MNIST demo we bench-marked digit image recognition inference using standard Tensorflow vs. Tensorflow Lite model and I was quite impressed with the almost 200x improvement. With Tensorflow ..

vs Tensorflow Lite …
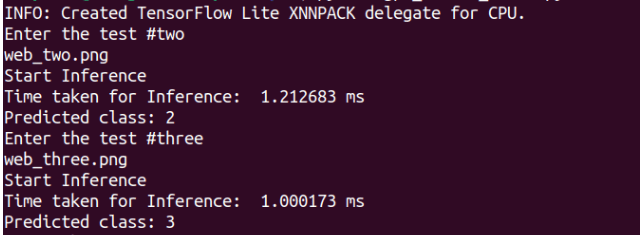
And our test images we were like following ..

Today I wanted to test if we can reduce further the inference time “at the edge” as we are running Debian on an industrial IMX8 gateway board. So we are going to compare the same digit image classification between Tensorflow Lite running on CPU (i.e the IMX8 SOC) and with ML ‘acceleration’ using a Google Coral M.2 Edge TPU card (4 TOPS using 2W of power).
We did have a bit of issue getting the software to integrate the EDGE TPU card, due to MSI-X not enabled in the kernel of our Linux 5.15, but it as sorted out by our board BSP team at Compulab.

According to Tensorflow TPU webpage, there are just 2 script modifications required for our Tensorflow Lite script to run inferences on the Edge TPU accelerator ..
- Instead of using
import tensorflow as tf, load thetflite_runtimepackage like this:import tflite_runtime.interpreter as tflite - Add the Edge TPU delegate when constructing the
Interpreter.For example, your TensorFlow Lite code will ordinarily have a line like this:interpreter = tflite.Interpreter(model_path)So change it to this:interpreter = tflite.Interpreter(model_path, experimental_delegates=[tflite.load_delegate('libedgetpu.so.1')])
Then we ran first the Tensorflow Lite on CPU (IMX8 SoC 4 x CortexA-53)
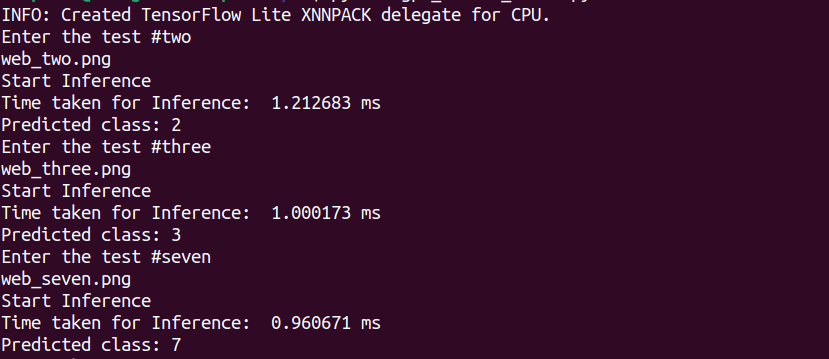
.. and with the Edge TPU accelerator

Shocker!
Inference time with the TPU accelerator board was actually SLOWER than just running with the SoC. My suspect is that perhaps, due to the test images used for our MNIST digit recognition experiment, the time taken to move data back and forth between the CPU and TPU likely out-weight the faster inference bit of the entire cycle? I need to ping the crew at PyCoral github and check if that is the case.
Next, I would want to run inference on more data/larger test object, perhaps an OpenCV object detector and see how much faster indeed adding an accelerator works in practice.
Related posts
Latest posts
- Complete Step by Step : Image Classification with TensorFlow and CNN
- Voice recognition using Tensorflow Lite in nRFS52840 development board
- Tested Bard vs ChatGPT to write a Python script for MNIST digit prediction!
- Edge TPU vs CPU for OpenCV Object Detection on IMX8
- Tensorflow Lite CPU vs TPU. Take Two!
